
#toc background: #f9f9f9;border: 1px solid #aaa;display: table;margin-bottom: 1em;padding: 1em;width: 350px; .toctitle font-weight: 700;text-align: center;
Content
Southwest Airlines charged that the display screen-scraping is Illegal since it’s an example of “Computer Fraud and Abuse” and has led to “Damage and Loss” and “Unauthorized Access” of Southwest’s web site. It additionally constitutes “Interference with Business Relations”, “Trespass”, and “Harmful Access by Computer”.
Also be ready that some information on wanted web sites may be secured (usernames, passwords or access codes), you can’t collect these knowledge as well. One more necessary thing about wholesome web scraping is the way of getting to the site and looking for wanted data. Experienced coders and attorneys recommend using crawlers which access web site data as a customer and by following paths much like a search engine. Even extra, this can be done without registering as a user and explicitly accepting any phrases.
Before scraping any website, do contact a lawyer as the technicalities concerned might make it unlawful. The key to avoiding acquiring insider data by means of internet scraping is to make sure that all the data scraped is data available to the general public.
In this text, it was showed that net scraping is the method of extraction of knowledge from the websites where all of the job is carried out the piece of code that is named ‘scrapper’. First of all, it sends a question of ‘GET’ to a selected web site. Then it parses the doc of HTML which depends on the desired outcome. After the completion of it, the scraper searches for the data you require inside the document, after which finally, transforms it into some particular format. Many websites will state of their terms of service that they do not permit scraping of their website.
When companies and individuals take pleasure in web scraping, they at instances cross the road and violate copyright norms and Terms of Service. Web scraping appears as an aggressive exercise that does not respect any ethical or authorized norms. This is the reason people find it troublesome to understand web scraping in a positive gentle. Regardless of if you’re using instruments for the coders or non-coders, proxies have their place on the planet of net scraping.
In most of the cases, the website filing the case end up losing. Web scraping is the usage of automation script to extract knowledge from websites. The automation script used for net scraping is named a web scraper. While there are some already developed internet scrapers in the market, most entrepreneurs concerned in it custom develop their own internet scrapers to deal with the peculiarities concerned of their distinctive instances. Regulations such as the EU General Data Protection Regulation (GDPR) have an effect on all corporations including monetary institutions and can result in hefty fines.
So, if you plan to publish the scraped information, you must make obtain request to the information homeowners or do some background analysis about web site policies as well as concerning the knowledge you will scrape. Remember that scraping information about individuals without their information may infringe on personal data safety legal guidelines. One attainable purpose could be that search engines like google and yahoo like Google are getting nearly all their data by scraping hundreds of thousands of public reachable web sites, additionally without reading and accepting these terms.
And in the European Union the case ofir.dk vs home.dk determined that regularly crawling and deep linking is permissible. The court ruled in favour of HiQ on condition that publicly accessible data is far short of hacking or “breaking and getting into” as thy put it. This is a landmark case in displaying that scraping is a perfectly reliable for companies to gather information when used accurately and responsibly. Data scrapers can put heavy hundreds on a website’s servers by asking for data far more occasions than a human does. You ought to care for the optimum fee of internet scraping process and do not have an effect on the performance and bandwidth of the web server in any way.
Again, while this doesn’t make doing so unlawful, the phrases of service do act a bit like a contract and could be used towards companies who do decide to scrape. Ethically talking, conducting any activity that another company has asked you to chorus from could possibly be considered poor practice. One of essentially the most highlighted circumstances of legal internet scraping was within the case of LinkedIn vs HiQ. HiQ is a data science firm that provide scraped knowledge to corporate HR departments. The business model is primarily centered on scraping publicly obtainable information from the LinkedIn community.
I have done some net scraping for my research, and I at all times assumed that this strategy was technically illegal, because it usually infringes the Terms of Service of information homeowners. The US Supreme Court case Feist Publications vs Rural Telephone Service established that scraping and republishing details like phone listings is allowed. A related case in Australia Telstra vs Phone Directories concluded that information can’t be copyrighted if there is no identifiable author.
What Are Web Scraping And Crawling?
Are you looking for CBD capsules? We have a wide selection of cbd pills made from best USA hemp from discomfort formula, energy formula, multivitamin formula and nighttime formula. Shop Canabidol CBD Oral Capsules from JustCBD CBD Shop. https://t.co/BA4efXMjzU pic.twitter.com/2tVV8OzaO6
— Creative Bear Tech (@CreativeBearTec) May 14, 2020
Fetching is the downloading of a page (which a browser does when a person views a page). Therefore, web crawling is a main component of internet scraping, to fetch pages for later processing. The content of a page could also be parsed, searched, reformatted, its information copied into a spreadsheet, and so on.
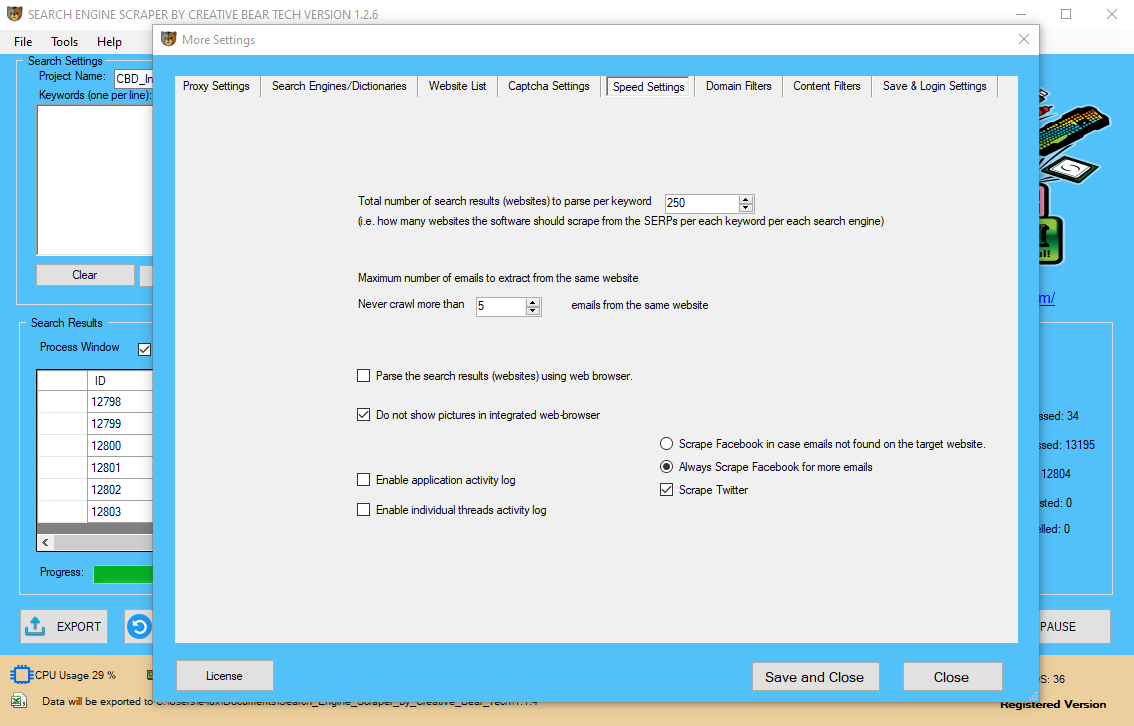
When constructing a scraper, we want it to work seamlessly forever and just deliver the information we want. The greatest problem in web scraping is that websites are continually changing. To keep up, we should always regulate our scraper so we are able to trust it delivers reliable and up-to-date knowledge.
In a 2014 case, filed in the United States District Court for the Eastern District of Pennsylvania, e-commerce web site QVC objected to the Pinterest-like purchasing aggregator Resultly’s ‘scraping of QVC’s web site for actual-time pricing information. QVC’s grievance alleges that the defendant disguised its internet crawler to masks its supply IP handle and thus prevented QVC from shortly repairing the problem. This is a particularly interesting scraping case as a result of QVC is looking for damages for the unavailability of their website, which QVC claims was caused by Resultly. Web scraping a web web page includes fetching it and extracting from it.
When scraping web sites and companies the legal half is commonly an enormous concern for companies, for internet scraping it greatly is dependent upon the nation a scraping person/company is from in addition to which data or web site is being scraped. Though the data published by most web sites is for public consumption, and it is legal for copying, it’s better to double-verify the web site’s insurance policies. You can legally use web scraping to access and purchase public, authorized data. Make certain that the knowledge on the sites you need don’t comprise personal knowledge. Web scraping can generally be accomplished without asking for permission of the owner of information if it doesn’t a violate the web site’s phrases of service.
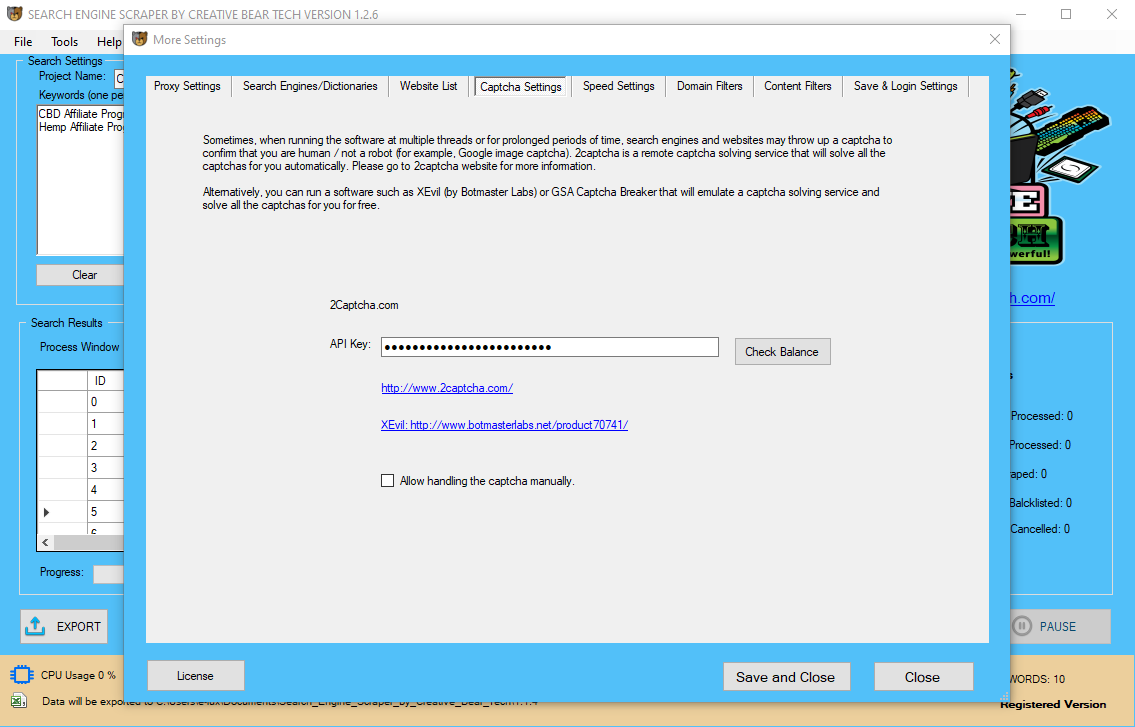
Methods To Prevent Web Scraping
Each web site has Terms of Service (ToS), you possibly can simply find that doc in the footer of the page and verify that there is no direct prohibition on scraping. If an internet site has written underneath its ToS that information assortment isn’t allowed, you risk being fined for net scraping, as a result of it is done with out the owner’s permission.
As the importance and worth of huge knowledge continues to rise, so does the variety of firms utilizing net crawling companies (or “spidersâ€) to obtain such information. Companies use spiders for display screen scraping web sites for data and knowledge which is copied or extracted by the spider for the company to then analyse or publish on its own website.
• Scrapers accesses website data as a customer, and by following paths similar to a search engine. This may be accomplished with out registering as a consumer (and explicitly accepting any phrases). Publicly available information gathering or scraping is not unlawful, if it have been unlawful, Google would not exist as an organization as a result of they scrape information from every website in the world. The most up-to-date of which HiQ vs LinkedIn, discovered that scraping information from a web site doesn’t violate anti-hacking legal guidelines so long as the data is public and the scraper hasn’t explicitly agreed to the web site’s phrases and circumstances in advance. The California U.S. District Court held that hiQ can use internet scapers to gather info from PUBLIC Linkedin data.
Web scrapers usually take one thing out of a page, to make use of it for an additional objective elsewhere. An instance could be to seek out and duplicate names and cellphone numbers, or companies and their URLs, to a listing (contact scraping).
The courtroom now gutted the truthful use clause that companies had used to defend internet scraping. The court decided that even small percentages, generally as little as 4.5% of the content material, are vital sufficient to not fall underneath fair use. The solely caveat the court docket made was based mostly on the straightforward incontrovertible fact that this knowledge was obtainable for buy. Southwest Airlines has additionally challenged display screen-scraping practices, and has involved both FareChase and one other agency, Outtask, in a legal claim.
Is Web Scraping Illegal? Depends On What The Meaning Of The Word Is
Beauty Products & Cosmetics Shops Email List and B2B Marketing Listhttps://t.co/EvfYHo4yj2
Our Beauty Industry Marketing List currently contains in excess of 300,000 business records. pic.twitter.com/X8F4RJOt4M
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
To shed some mild on this grey space, I sat down with Sanaea Daruwalla, Head of Legal at Scrapinghub, to get her insights on how Scrapinghub ensures our purchasers are scraping private data in a GDPR compliant means. Most web servers will automatically block your IP, stopping further access to its pages, in case this occurs. In late 2019, the US Court of Appeals denied LinkedIn’s request to prevent HiQ, an analytics company, from scraping its data.
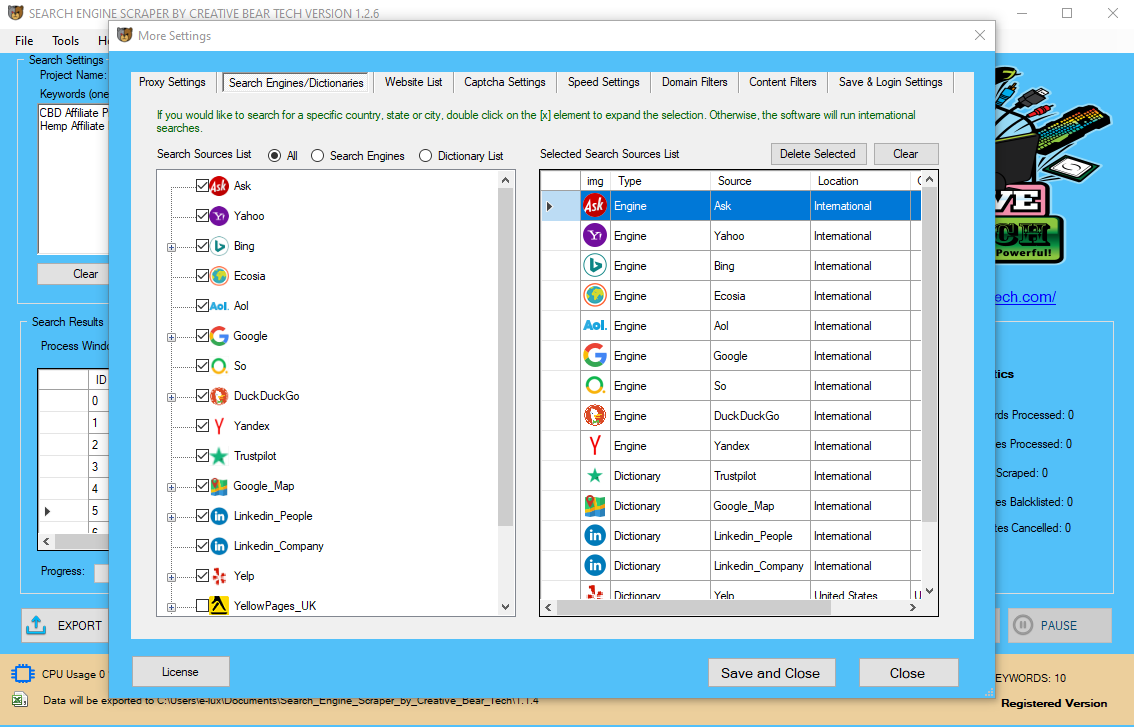
Consequently, the historic choice showed that any information that is publicly obtainable and isn’t copyrighted is legally valid for using net crawlers. Much analysis information nowadays is sourced immediately from the Web, either from conventional web sites or from social media platforms. Economists, sociologists, and geographers typically depend on internet scraping to gather massive datasets in regards to the behaviour of many human systems. This consists of, for example, getting flight costs from Expedia to mannequin transport market dynamics, amassing Facebook messages to analyse hate speech, and scraping Airbnb listings to study the housing crisis in London.
- You can legally use net scraping to access and purchase public, approved knowledge.
- Web scraping can usually be carried out without asking for permission of the owner of information if it does not a violate the website’s terms of service.
- Make positive that the information on the websites you want don’t comprise personal knowledge.
- Though the info revealed by most web sites is for public consumption, and it is legal for copying, it’s higher to double-check the website’s insurance policies.
- Each website has Terms of Service (ToS), you possibly can simply find that document in the footer of the page and examine that there isn’t a direct prohibition on scraping.
- When scraping web sites and companies the legal part is commonly a big concern for corporations, for web scraping it significantly is dependent upon the nation a scraping user/firm is from as well as which information or web site is being scraped.
Websites are not looking for their data scraped, especially when done in an automatic means. When the term internet scraping is mentioned, what comes into the thoughts of many is whether Is web scraping legal? it is legal. There had been quite a few courtroom circumstances where websites file lawsuits towards businesses and people web scraping their net content.
Google and different search engines like google and yahoo use bots to scrape sites on the web and rank content material accordingly for their customers. Web scraping permits analyzing a large volume of data that would be unimaginable for people to process in such a quick method. The best examples of display screen scraping are value comparability sites, such as airline flight comparison websites. The comparison web site makes use of a spider to scan the web sites of the different airlines. The data scraped from these web sites is then compiled on the comparison website, offering shoppers with a very handy device.
The largest public known incident of a search engine being scraped occurred in 2011 when Microsoft was caught scraping unknown keywords from Google for their very own, rather new Bing service. This is as a result of the knowledge been scraped is publicly obtainable on their web site.
Legal Issues
Each case will flip by itself facts though and this is very a lot dependent upon what information is scraped from the web sites. Companies should watch out for contractual provisions which they have agreed to in respect of an internet site’s terms of use – these might prohibit the person from taking and utilizing the data off the positioning. If you are contemplating commencing a web scraping project for your small business that might extract personal data from public websites and also you want to ensure it’s GDPR compliant, then don’t hesitate to succeed in out to us. Our engineering group of 60+ crawl engineers and information scientists can build a customized net scraping solution in your particular needs. Websites have their very own ‘Terms of use’ and Copyright details whose hyperlinks you can easily discover within the website house page itself.
This cost is a felony violation that’s on par with hacking or denial of service assaults and carries up to a 15-yr sentence for each cost. Tons of people and companies are working their own internet scrapers right now. So a lot that this has been inflicting complications for companies whose websites are scraped, like social networks (e.g. Facebook, LinkedIn, and so on.) and online stores (e.g. Amazon). This might be why Facebook has separate phrases for automated data assortment. In the United States district court for the eastern district of Virginia, the court docket ruled that the terms of use ought to be delivered to the users’ attention In order for a browse wrap contract or license to be enforced.
Step 3: Do You Have A Lawful Reason To Scrape Their Personal Data?
Scraping knowledge from the online does certainly have some moral, authorized, and technical limitations. In May 2018, the General Data Protection Regulation (GDPR) was enforced, creating challenges for all firms working with private knowledge of EU residents. In June 2019, online media reported on the primary GDPR fine issued in Poland for a failure to tell information subjects in regards to the processing of their information. However, web scraping is authorized for authorized functions and when it’s compliant with the GDPR.
As a end result, much of the current legal precedent for net scraping is of little relevance to various data for finance, requiring financial companies to dig a bit deeper into the case law for instances related to their use case. However, as talked about above, while many instances exist relating to those causes of motion, no clear normal has emerged across the board. Like the usage of copyrighted images and songs, simply because the data is publically available on the web doesn’t imply it is legal for it to be scraped without the proprietor’s consent. You could possibly be infringing the proprietor’s copyright by scraping their data. This query raises controversy among attorneys and practitioners.
An appeals courtroom located in California, US, right now saidit’s not illegal to scrape data from public web sites without any prior approval. Web scraping refers back to the strategy of accumulating large troves of data with the usage of internet crawlers – scripts designed to carry info from net pages. Facebook and LinkedIn are two highly popular sites that many individuals are thinking about getting information from. However, each these websites block automated net crawling through their robots.txt file and LinkedIn’s authorized disputes with corporations that have scraped knowledge off them have been a scorching subject on business/tech media retailers.
Still, there is a change within the legal landscape with respect to Data Scraping. Website owners will need to study how they management or limit entry to content they gather from users. Web scraping content from a competitor’s website may be thought-about fair sport for the reason that information is within the public area. However, there have been legal challenges and web scraping is at present a authorized gray area.
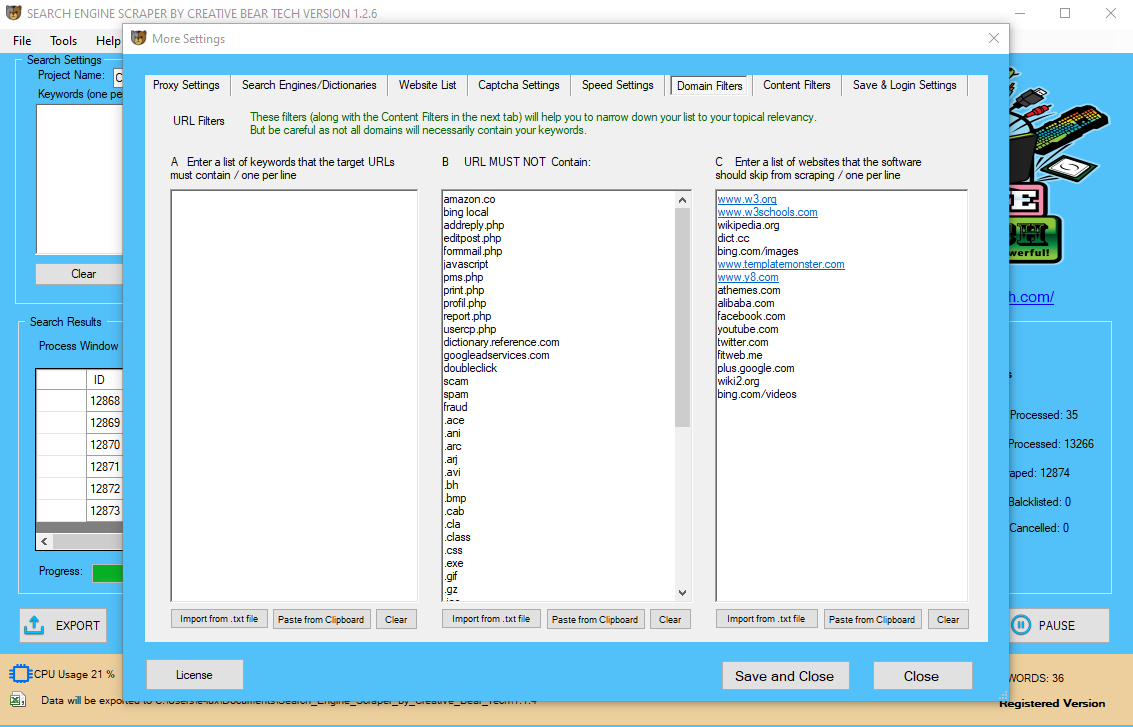
So, a legal internet scraping might scan and duplicate any public information which is available to the regular user however cannot, for example, injury the positioning coding, destroy secured digital obstacles and interfere with normal web site operation in any way. In addition to ToS, all websites have Copyright particulars, which net scraping users should respect as properly. Before copying any content material, make sure that the information you might be about to extract just isn’t copyrighted, together with the rights to text, images, databases, and emblems. Avoid republish scraped information or any data-units with out verifying the information license, or without having written consent from the copyright holder. If some data isn’t allowed to be used for business functions because of copyright, you need to steer clear from it.
Explode your B2B sales with our Global Vape Shop Database and Vape Store Email List. Our Global Vape Shop Database contains contact details of over 22,000 cbd and vape storeshttps://t.co/EL3bPjdO91 pic.twitter.com/JbEH006Kc1
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
If consent is withdrawn, or a DSAR is obtained to delete private knowledge, then the company who scraped this information must either delete or anonymize this personal knowledge since you not have a legal basis to hold it. As a outcome, when Scrapinghub is evaluating a scraping project we frequently work with consumer firms to minimise the amount of private knowledge they extract from a website and to outline retention intervals to ensure they comply with GDPR. You ought to adopt an identical evaluation course of for your personal scraping initiatives to make sure you comply with GDPR’s minimisation requirements. Although this lawful purpose is viable for internet scrapers, for many corporations it is going to be very tough for them to reveal that they have a legitimate interest in scraping someone’s private information. However, it’s going to nonetheless allow some companies to scrape the non-public knowledge of EU residents if they have obtained their express content to do so.
It’s a compulsion for many types of businesses to scrape knowledge and analyze it. But it’s equally true that many people are not sure of the legality of internet scraping. The major concern of all these cases is the query of whether the Terms of Service listed on many web sites that forbid net scraping (or automatic access) are legally enforceable. So we need to wait and see whether knowledge scraping of public information is legal.
One of the best ways to prevent scraping is to state it categorically on your Terms of Service that net scraping isn’t allowed. You can sue any scrapers if they do select to ignore your acknowledged terms. Take, for instance, LinkedIn suing scrapers, and contemplating them to be hackers since they extracted users’ data via automated requests.
The customers of web scraping software/methods ought to respect the phrases of use and copyright statements of goal web sites. These refer mainly to how their data can be used and how their website may be accessed.
However, if the scraped knowledge is a inventive work, then usually just the way or format by which it’s presented is copyrighted. So, in case you scrape ‘information’ from the work, modify it and current originally, that’s authorized. If the information is extracted in your personal use and evaluation, then web scraping is legal and ethical. But if you will use it as your content and publish it in your website without any attributing to authentic data house owners, then it’s fully against the interest of knowledge topics and it’s neither ethical, nor legal.
The Key issue in the Linkedin case was that hiQ may entry and scrape only public information that was not protected by any authorization approach (such as password protected). Interestingly, the Court granted a preliminary injunction to prohibit Linkedin from using electronic blocking strategies designed to stop hiQ from scraping info from public linkedin profiles. Simply, crawl or scrape websites beneath the ambit of the regulation — like RESPECTING their Terms of Service (TOS). Some stakeholders have continued to look endlessly for answers to “Is it authorized to scrape a website? †Some consider that internet scraping is against the law; bots steal information and use it to the advantage of the proprietor — making a profit in the course of at the expense of the web site proprietor.
Under laws like GDPR, you usually want a lawful foundation to process personal information, which might embrace consent, contractual settlement, or reliable curiosity. Absent certainly one of these lawful basises, you shouldn’t be scraping personal knowledge. However, this analysis will range from area to region, so please ensure you are familiar with the data safety laws in the region by which you operate earlier than scraping personal data.
The data is used within analytics to determine key components like whether an worker is likely to go away for an additional company or what employees would love their coaching departments to spend money on. Andrew Auernheimer was convicted of hacking based mostly on the act of web scraping.
Although the information was unprotected and publically out there through AT&T’s website, the truth that he wrote internet scrapers to reap that knowledge in mass amounted to “brute drive attackâ€. He did not need to consent to phrases of service to deploy his bots and conduct the net scraping. He didn’t even financially achieve from the aggregation of the information. Most importantly, it was buggy programing by AT&T that exposed this data within the first place.
If you do, most web servers will just automatically block your IP, preventing additional entry to its web pages. As the courts attempt to further decide the legality of scraping, corporations are nonetheless having their knowledge stolen and the business logic of their web sites abused. Instead of trying to the regulation to eventually solve this know-how drawback, it’s time to start out solving it with anti-bot and anti-scraping technology at present. Previously, for academic, personal, or info aggregation folks might rely on honest use and use web scrapers.
Exercising and Running Outside during Covid-19 (Coronavirus) Lockdown with CBD Oil Tinctures https://t.co/ZcOGpdHQa0 @JustCbd pic.twitter.com/emZMsrbrCk
— Creative Bear Tech (@CreativeBearTec) May 14, 2020
Typically, if the data is out there on a public website that any individual can go to and see, you’re on protected footing. The risk of acquiring insider data increases when the information isn’t public – for example, information behind a login or paywall. It’s common knowledge that web scraping is a means of extracting knowledge from web sites.
What Is Web Scraping & Is It Legal?
JustCBD CBD Bath Bombs & Hemp Soap – CBD SkinCare and Beauty @JustCbd https://t.co/UvK0e9O2c9 pic.twitter.com/P9WBRC30P6
— Creative Bear Tech (@CreativeBearTec) April 27, 2020
A legal case gained by Google against Microsoft would possibly put their complete business as danger. In common, traders are in search of to gather scraping internet knowledge to realize a better understanding of the wider tendencies impacting a market. Not to redistribute or compete with the unique owner of the data.